Estruturas de Dados I
Filas de Prioridade
14/10/2020 - rev. 18/06/2025
Filas de Prioridade na Computação
Filas de Prioridade são estruturas fundamentais na própria computação. Também são úteis na implementações de algoritmos em grafos, como a busca por árvores geradoras mínimas (aulas futuras).
Por exemplo, quando se envia pacotes de dados a roteadores, existem mecanismos que podem tirar vantagem de valores de prioridade entre pacotes (dados de voz e de download, etc). Uma interpretação cotidiana poderia ser uma fila prioritária por idade, na qual os indivíduos mais velhos seriam sempre atendidos antes dos mais novos.

Implementações
A implementação do TAD Fila de Prioridade geralmente se dá através de uma implementação de árvores de prioridade denominada heap binário. O heap (ou min heap) é uma árvore binária completa, ou seja, facilmente representada como um vetor, com a seguinte propriedade de heap:
- se é pai de , então


Implementação heap com vetor
Apesar de sua estrutura de árvore, podemos representá-la eficientemente com um vetor, numa implementação puramente sequencial.
Representação por níveis com N=6 e
MAX_N=7:
| 2 | 3 | 6 | 9 | 4 | 7 | |
0 1 2 3 4 5 6Assim, os dados sempre estarão em um espaço contíguo de memória.
Algoritmo FilaPrioridadeTAD frente
A operação frente retorna o elemento mais prioritário do
heap. Felizmente, ele sempre será a raiz da árvore!
Desafio: verifique se é possível o elemento mais prioritário não estar na raiz do heap.
Algoritmo FilaPrioridadeTAD remove - Parte 1/5
A operação remove em adiciona um novo elemento de acordo
com sua prioridade. Como manter a corretude das propriedades do
heap?
Exemplo: como remover o elemento ?
Algoritmo FilaPrioridadeTAD remove - Parte 2/5
Para manter a corretude das propriedades do heap, em especial, de uma árvore completa, trocamos o primeiro com o último elemento do vetor.
Exemplo: como remover o elemento ?

Algoritmo FilaPrioridadeTAD remove - Parte 3/5
Após a troca do último elemento com a raiz, perdemos a propriedade heap.
Como corrigir a árvore? Solução: trocas sucessivas descendo até uma folha.


Mas qual filho trocar? Solução: sempre existe um filho certo, sendo ele o mais prioritário entre os irmãos. Assim trocamos o 7 pelo 3.
Algoritmo FilaPrioridadeTAD remove - Parte 4/5
Ainda assim, seguimos sem a propriedade heap.
Como corrigir a árvore? Solução: trocas sucessivas descendo até uma folha.


Mas qual filho trocar? Solução: sempre existe um filho certo, sendo ele o mais prioritário entre os irmãos. Assim trocamos o 7 pelo 4.
Algoritmo FilaPrioridadeTAD remove - Parte 5/5
Finalmente, recuperamos a propriedade heap.
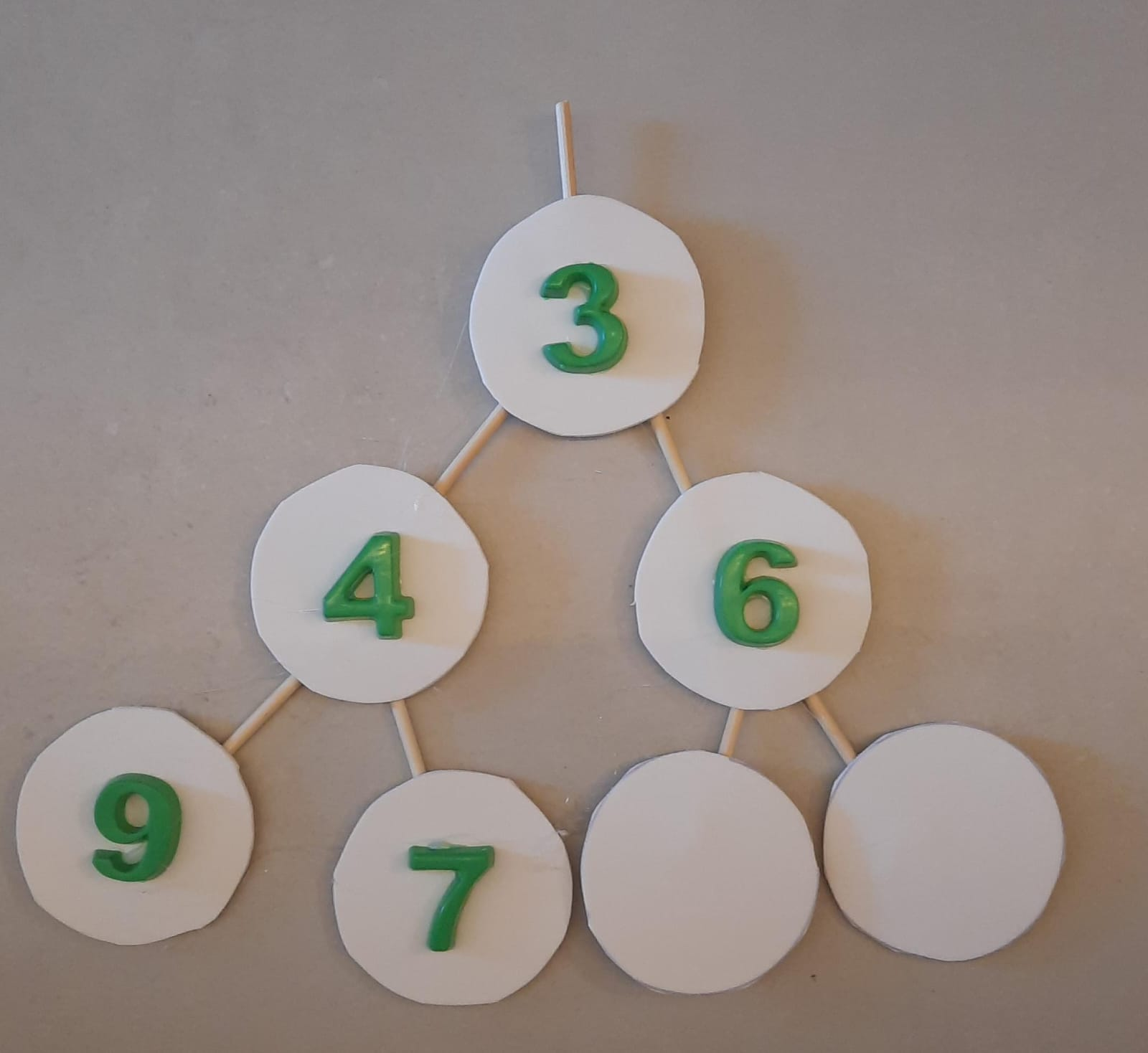

Chegamos na folha, não é preciso mais efetuar trocas.
Algoritmo FilaPrioridadeTAD insere - Parte 1/5
A operação insere em adiciona um novo elemento de acordo
com sua prioridade. Como manter a corretude das propriedades do
heap?
Exemplo: como inserir o elemento ?
Solução: precisamos manter a árvore completa!
Algoritmo FilaPrioridadeTAD insere - Parte 2/5
Para manter a corretude das propriedades do heap, em especial, de uma árvore completa, adicionamos o elemento na última posição do vetor.
Exemplo: como inserir o elemento ?


Algoritmo FilaPrioridadeTAD insere - Parte 3/5
Mas agora perdemos a propriedade de heap.
Exemplo: como inserir o elemento ?
Como corrigir a árvore? Solução: trocas sucessivas subindo até a raiz.
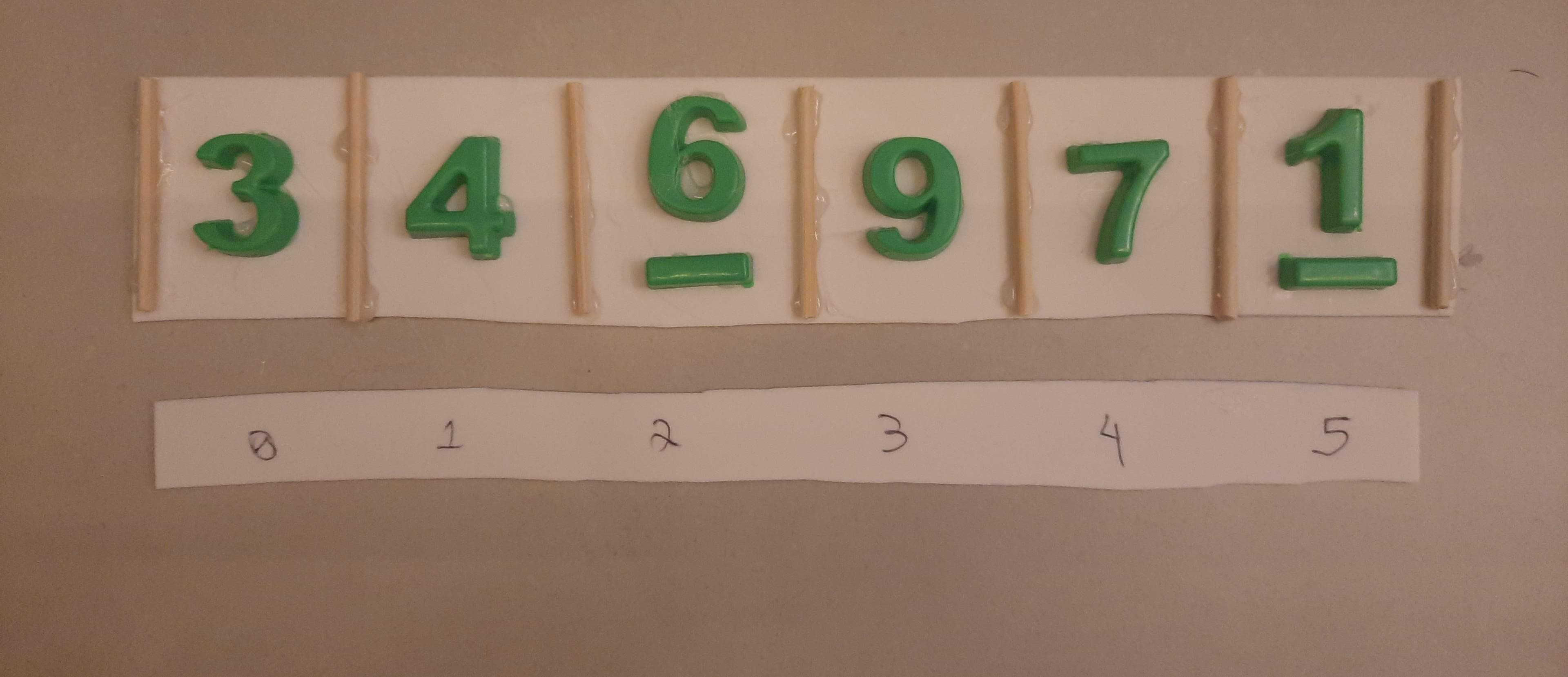
Mas onde está o pai da posição no vetor? Fácil,
Algoritmo FilaPrioridadeTAD insere - Parte 4/5
Mas seguimos sem a propriedade de heap.
Exemplo: como inserir o elemento ?
Como corrigir a árvore? Solução: trocas sucessivas subindo até a raiz.
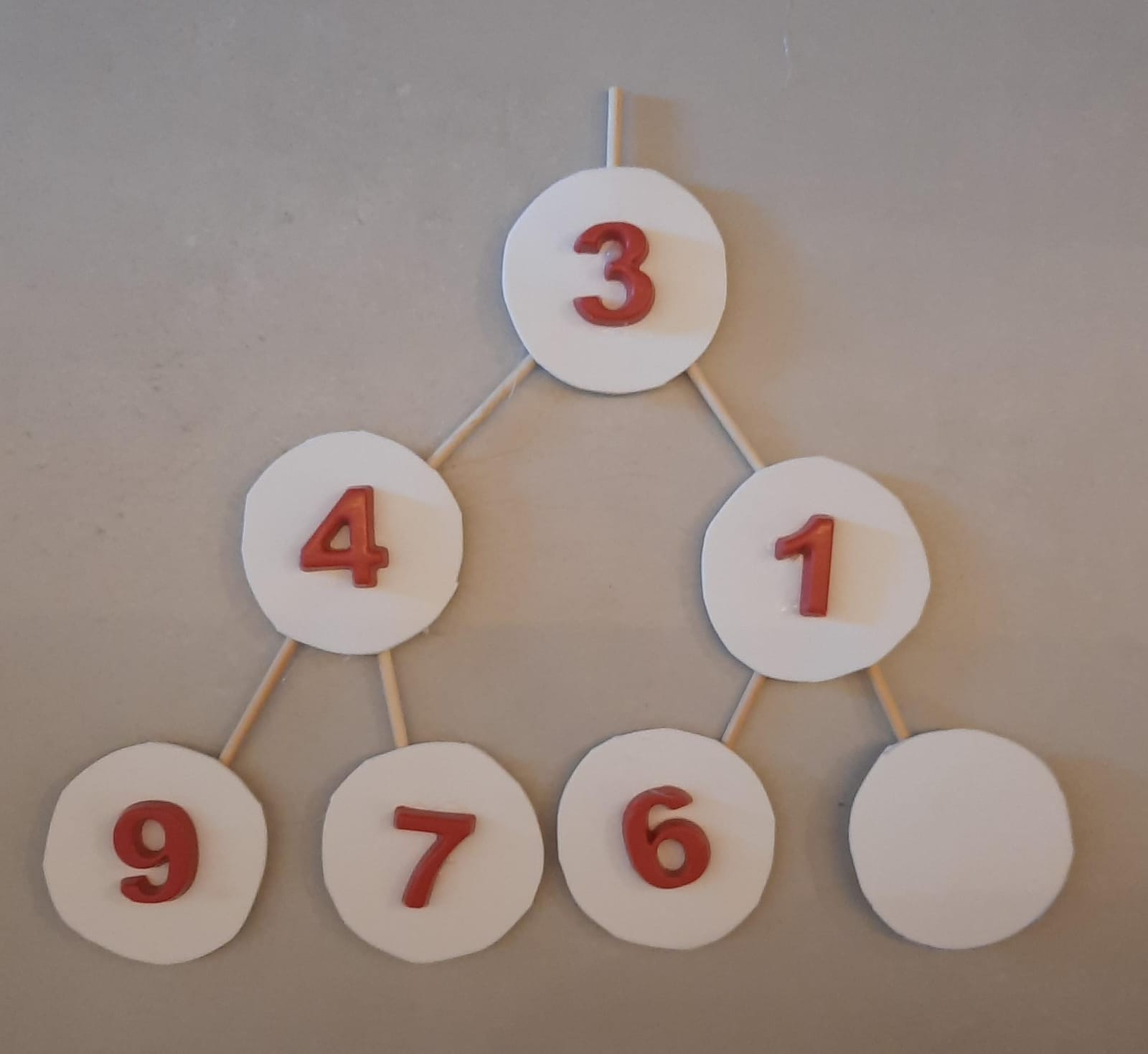

Trocamos então o elemento na posição pelo seu pai.
Algoritmo FilaPrioridadeTAD insere - Parte 5/5
Finalmente, recuperamos a propriedade de heap.
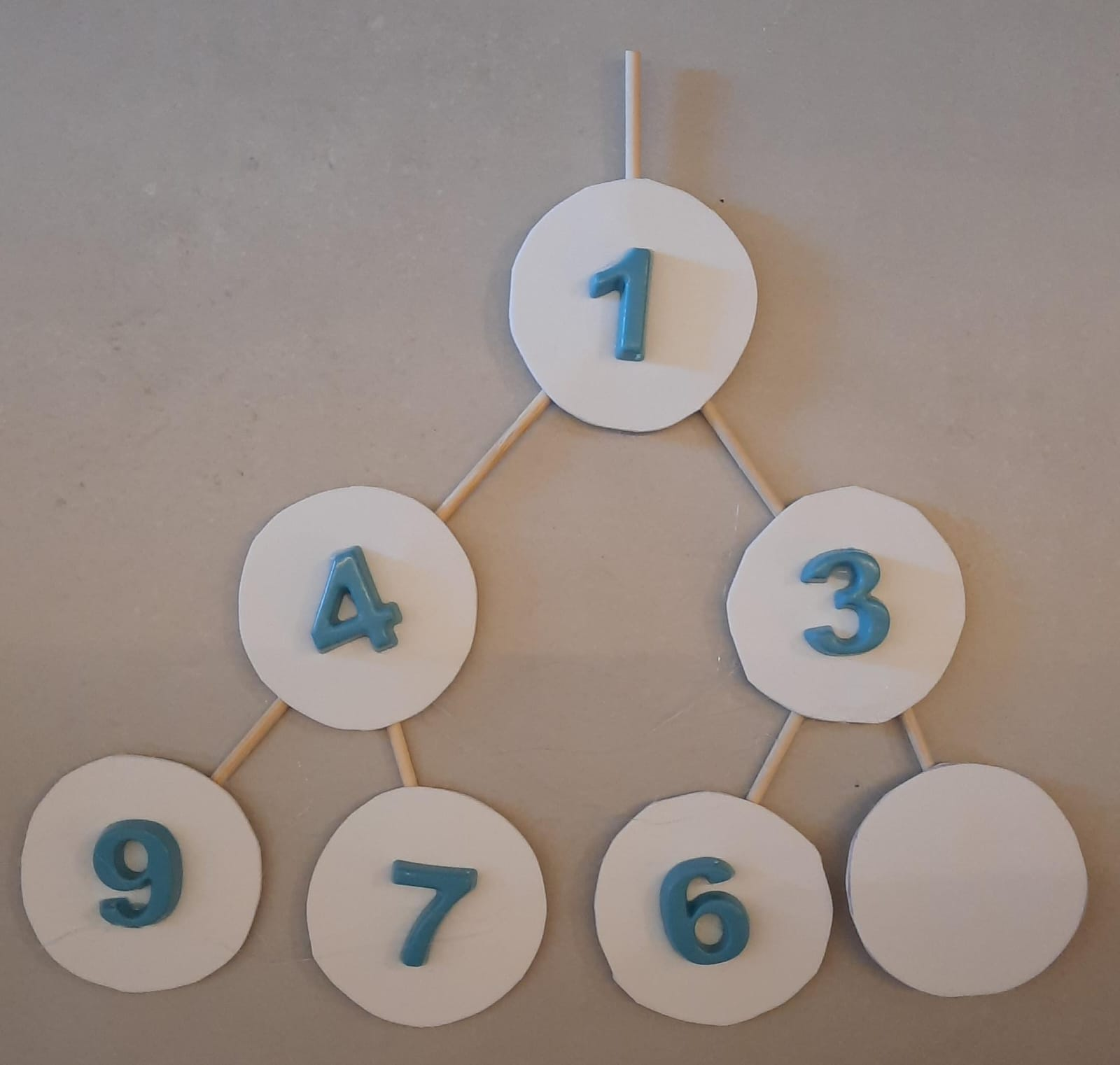
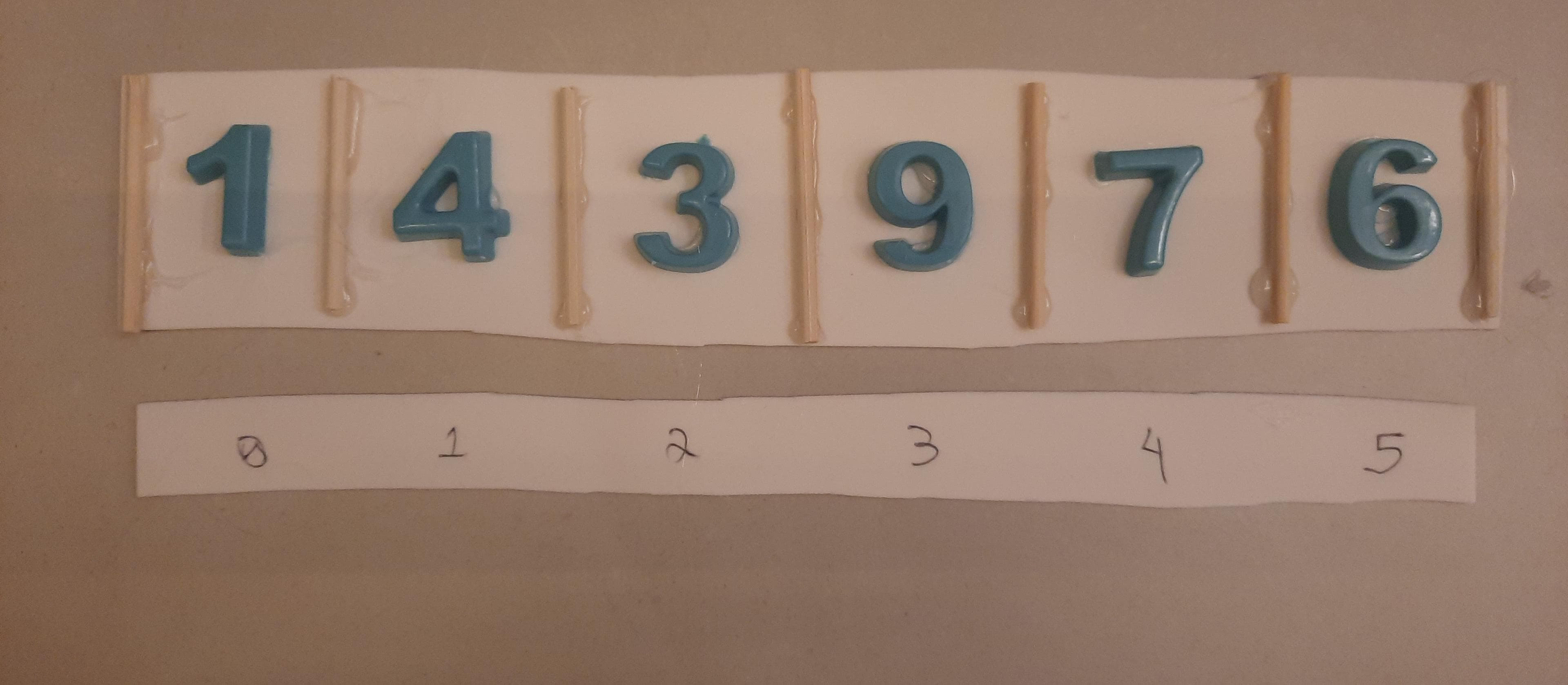
Finalizamos a inserção do elemento .
Implementação Heap1 - frente
A operação frente retorna a raiz do heap, ou seja, o
primeiro elemento. Este é sempre o mais prioritário.
auto Heap1::frente() -> int {
return v[0];
}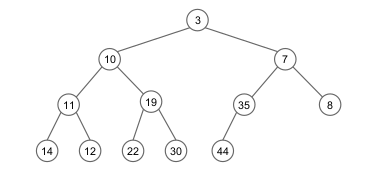
Representação por níveis (árvore completa):
| 3* | 10 | 7 | 11 | 19 | 35 | 8 | 14 | 12 | 22 | 30 | 44 |Implementação Heap1 - pai e filho
Métodos auxiliares pai e filho.
auto Heap1::pai(int pos) -> int {
return (pos - 1) / 2;
}
auto Heap1::filho1(int pos) -> int {
return (2 * pos) + 1;
}
auto Heap1::filho2(int pos) -> int {
return filho1(pos) + 1;
}
Representação por níveis:
| 3 | 10 | 7 | 11 | 19 | 35 | ...
0 1 2 3 4 5Implementação Heap1 - sobe
A operação sobe compara sistematicamente um nó com seu
pai, efetuando trocas enquanto a prioridade estiver incorreta. Custo:
proporcional ao nível.
auto Heap1::sobe(int pos) -> void {
int p = pai(pos);
while (pos > 0) {
// compara filho com pai
if (v[pos] >= v[p])
break;
troca(p, pos, v);
pos = p; // repete
p = pai(pos);
}
}
Representação por níveis:
| 3 | 10 | 7 | 11 | 19 | 35 | ...
| 8 | 14 | 12 | 22 | 30 | 44 |Implementação Heap1 - insere
O método insere coloca o novo elemento no final do heap
e invoca a operação sobe. Custo: altura da árvore.
auto Heap1::insere(int pos) -> void {
v[N] = pos;
N++;
sobe(N-1);
}
Representação por níveis:
| 3 | 10 | 7 | 11 | 19 | 35 | ...
| 8 | 14 | 12 | 22 | 30 | 44 |Implementação Heap1 - desce
A operação desce compara um nó com seus filhos, trocando
enquanto a prioridade for incorreta. Custo: proporcional ao nível.
auto Heap1::desce(int pos) -> void {
int f = filho1(pos);
while (f < N) {
// existe segundo filho?
if ((f < N-1) && (v[f+1]<v[f]))
f = f + 1;
if (v[f] >= v[pos]) break;
troca(f, pos, v);
pos = f; f = filho1(pos);
}
}
Representação por níveis:
| 3 | 10 | 7 | 11 | 19 | 35 | ...
| 8 | 14 | 12 | 22 | 30 | 44 |Implementação Heap1 - remove
O método remove troca o primeiro com último elemento e
invoca a operação desce. Custo: altura da árvore.
auto Heap1::remove() -> int {
troca(0, N-1, v);
N--;
desce(0);
return v[N];
}
Representação por níveis:
| 3 | 10 | 7 | 11 | 19 | 35 | ...
| 8 | 14 | 12 | 22 | 30 | 44 |Heapify / Constroi
A construção de um heap através de um vetor é chamada de heapify. É possível efetuar a construção de forma iterativa, através dos métodos sobe ou desce.
Como vimos anteriormente, o método sobe custa, no máximo, o nível do nó, enquanto o método desce custa, no máximo, a altura do nó.
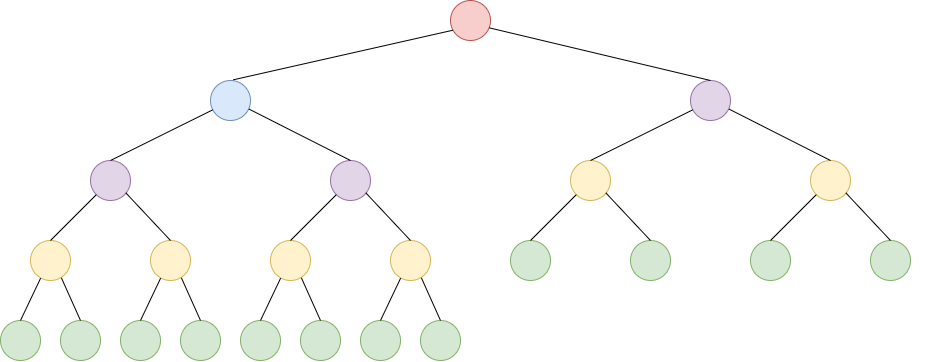
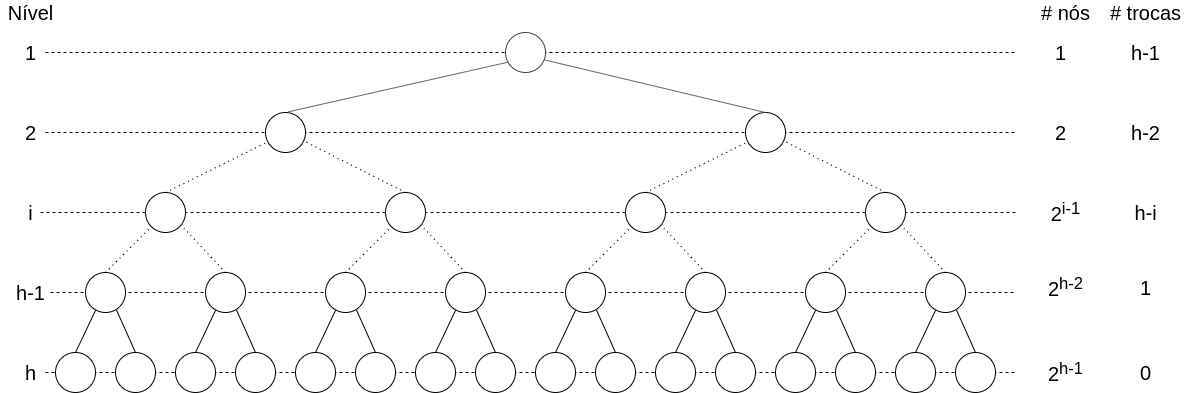
Veja as alturas dos nós (N=23): vermelho(5), azul(4), roxo(3), amarelo(2), verde(1). Metade dos nós (12) tem altura 1.
Heapify com sobe
A construção do heap () com o método sobe opera sequencialmente a partir dos nós , e a raiz não efetua nenhuma troca. Cada elemento folha () irá incorrer em trocas, no pior caso, tendo assim complexidade .
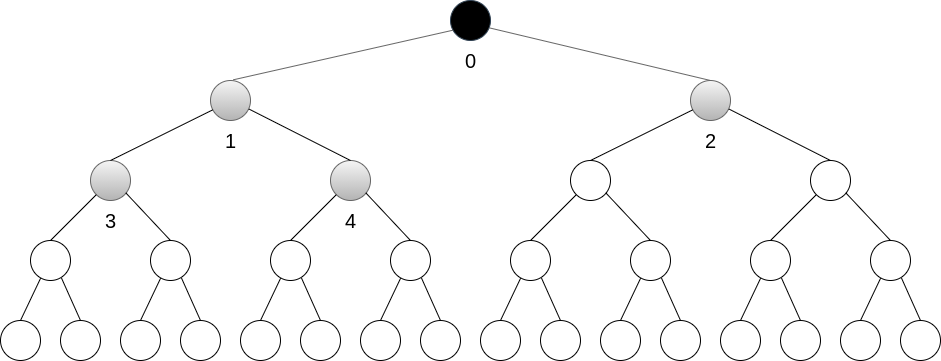
nós: | 0 | 1 | 2 | 3 | 4 | ... ->Heapify com desce
A construção do heap () com o método desce toma vantagem de que as folhas () tem altura 1, portanto não necessitando de troca alguma. O método opera sequencialmente em ordem decrescente a partir do nó como . Note que um único elemento (a raiz) irá incorrer em trocas, sendo a complexidade superestimada neste caso.
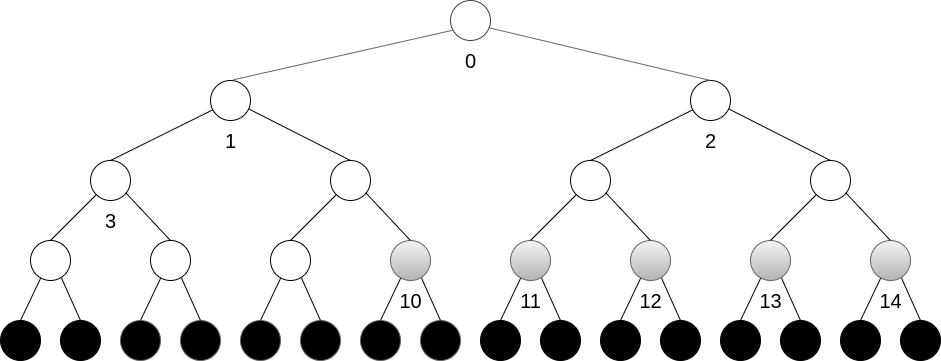
nós: | 0 | 1 | ... <- | 10 | 11 | 12 | 13 | 14 | ...Análise do Método Heapify com desce
Consideramos uma árvore com nós e níveis. No nível 1, um único nó (a raiz) efetua trocas, no pior caso. Por outro lado, existem folhas que não fazem nenhuma troca.
De forma geral, no nível , cada um dos nós efetuam trocas, no pior caso, totalizando trocas.